I was reading this article by Marek Majkowski recently and a few terms went over my head. So had fun digging and yak-shaving and this blog post is the result of it. My attempt here is to collect enough arms in one place so as to tackle that post with ease. Let’s go…
I/O Models
The problem we are trying to solve is having multiple I/O jobs to juggle at the same time. How do we know which file descriptor is ready to read, write, or errored out?
Sure, we can go in a loop and check if something is ready or not (which is non-blocking). Or infinitely wait till one is ready and forget the rest till this fd is ready (blocking).
Blocking I/O
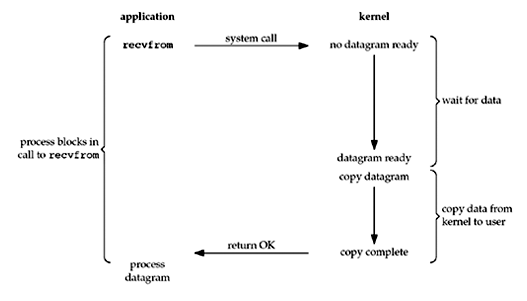
Unix Network Programming Fig 6.1
Non Blocking I/O
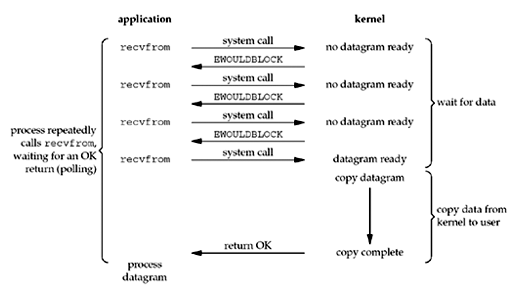
Unix Network Programming Fig 6.2
But there are more I/O models possible out there:
I/O Multiplexing Model
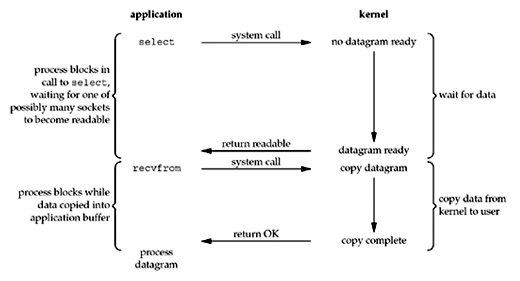
Unix Network Programming Fig 6.3
As we can see, in I/O multiplexing the process blocks on a method call (like select/poll/epoll) and the kernel wakes up the blocking process when some I/O is ready. The process gets the file descriptors that are ready to be read, written, or exception.
Signal-Driven I/O Model
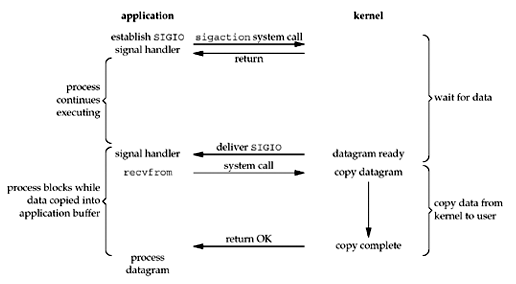
Unix Network Programming Fig 6.4
The signal-driven I/O model uses signals, telling the kernel to notify us with the SIGIO signal when the descriptor is ready.
Asynchronous I/O Model
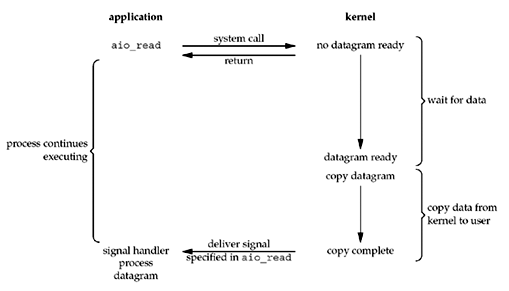
Unix Network Programming Fig 6.5
- The Async I/O functions (defined by the POSIX specification) work by telling the kernel to start the operation and to notify us when the entire operation (including the copy of the data from the kernel to our buffer) is complete. The main difference between this model and the signal-driven I/O model is that with signal-driven I/O, the kernel tells us when an I/O operation can be initiated, but with asynchronous I/O, the kernel tells us when an I/O operation is complete
- the POSIX asynchronous I/O functions begin with
aio_orlio_
I/O Multiplexing
select(2)
Let’s start by looking at the simplest and earliest I/O Multiplexing model, select

man select
- The
selectfunction allows the process to instruct the kernel to either:- Wait for any one of multiple events to occur and to wake up the process only when one or more of these events occurs, or
- When a specified amount of time has passed.
- The three middle arguments, readfds, writefds, and exceptfds, specify the descriptors that we want the kernel to test for reading, writing, and exception conditions.
Here’s a simple TCP server using select:
import socket
import select
import os
SERVER_HOST = 'localhost'
SERVER_PORT = 8080
MAX_CLIENTS = 10
def child_process(client_sockets, master_socket, id):
while True:
read_sockets, _, _ = select.select(client_sockets, [], [])
for sock in read_sockets:
if sock == master_socket:
try:
client_socket, addr = master_socket.accept()
client_socket.setblocking(False)
print(f"New conection {addr} in process {id}")
client_sockets.append(client_socket)
except:
break
else:
data = sock.recv(1024)
if not data:
sock.close()
client_sockets.remove(sock)
else:
sock.send(data)
if __name__ == '__main__':
master_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
master_socket.bind((SERVER_HOST, SERVER_PORT))
master_socket.listen(MAX_CLIENTS)
master_socket.setblocking(False)
client_sockets = [master_socket]
for i in range(100):
pid = os.fork()
if pid == 0:
child_process(client_sockets, master_socket, i)
os.wait()
select has a few issues though:
- Whenever your process enters the select(), the kernel must iterate through the passed file descriptors, check their state, and register callbacks. Then when an event on any of the fd’s happens, the kernel must iterate again to deregister the callbacks. Basically on the kernel side entering and exiting select() is a heavyweight operation, requiring touching many pointers, and thrashing the processor cache, and there is no way around it.
- epoll was introduced to fix this issue
- Another issue is the scalability of sharing sockets between processes. In the traditional model, the kernel must wake up all the processes hanging on a socket, even if there is only a single event to deliver. This results in a thundering herd problem and plenty of wasteful process wakeups.
EPOLLEXCLUSIVEwith epoll is used to solve this- This issue can also be solved with SO_REUSEPORT socket sharding as seen in the nginx post
epoll(7)
- Does a similar function as select and is more similar to
poll(2)

man 7 epoll
- epoll maintains a red-black tree data structure for faster lookups and adds. This along with its semantics of process manually registering and deregistering the fds make it better than select.
- epoll provides either level-triggered or edge-triggered mode
Scenario:
(1) The file descriptor that represents the read side of a pipe (rfd - read file descr.) is registered on the epoll instance. (2) A pipe writer writes 2 kB of data on the write side of the pipe. (3) A call to epoll_wait(2) is done that will return rfd as a ready file descriptor. (4) The pipe reader reads 1 kB of data from rfd. (5) A call to epoll_wait(2) is done.
- Edge-triggered: In the above scenario, if the rfd is added using EPOLLET flag, it is edge-triggered. When (5) happens, it is blocked. Here, is it assumed that whichever process first got the rfd is supposed to consume the whole data from the buffer.
- When multiple threads are waiting on the
epoll.wait()and marked interest on the same fd, only one of them is awoken on the activation of that fd - EPOLLONESHOT is a flag that can be used by the caller to let the kernel know that it should disable the associated fd after the successful receipt of an event from
epoll. wait(). It becomes the caller’s responsibility to rearm the fd using epoll_ctl - The suggested way to use epoll as an edge-triggered (EPOLLET) interface is as follows: (1) with nonblocking file descriptors; and (2) by waiting for an event only after read(2) or write(2) return EAGAIN.
- When multiple threads are waiting on the
- Level-triggered: This is like a normal
pollfunction and on (5), returns the fds if they have data- To be noted, even if multiple processes are allowed, usage of locks and
acceptreturning to one of them and others receiving EAGAIN are some solutions that handle concurrency in these cases. - EPOLLEXCLUSIVE - When a wakeup event occurs and multiple epoll file descriptors are attached to the same target file using EPOLLEXCLUSIVE, one or more of the epoll file descriptors will receive an event with epoll_wait(2). The default in this scenario (when EPOLLEXCLUSIVE is not set) is for all epoll file descriptors to receive an event. EPOLLEXCLUSIVE is thus useful for avoiding thundering herd problems in certain scenarios.
- To be noted, even if multiple processes are allowed, usage of locks and
Here’s the same sample with epoll in python (Exercise: Do this in C to understand the specification more in depth)
import socket
import select
import os
# To avoid thundering-herd problem. This requires kernel 4.5+.
EPOLLEXCLUSIVE = 1<<28
def child_process(epoll, sock, id):
while True:
try:
epoll.poll()
except IOError:
continue
while True:
try:
cd, _ = sock.accept()
print(f"worker {id}")
except socket.error:
break
except Exception as e:
print(f"Some other exp {e}")
break
cd.close()
if __name__ == '__main__':
# Create and bind socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8080))
sock.listen(10)
sock.setblocking(False)
# Fork child processes
for i in range(3):
pid = os.fork()
if pid == 0:
# Create epoll instance
epoll = select.epoll()
epoll.register(sock, select.EPOLLIN | EPOLLEXCLUSIVE)
child_process(epoll, sock, i)
os.wait()
Closing Notes:
- That’s it. This article was just ammo. Now go ahead and read the article for the actual killing. Also check out the combined queue model and the video which is really cool
- After doing all this research, I have a nagging sense that I am barely scratching the surface. OMG! There’s so much more. But you got to start somewhere right?
- Another interesting thing to me was Gunicorn still uses select and is prone to the thundering herd problem. It is well documented in their website. This issue thread discussing looks like they are moving towards using epoll and
--thunder-lockoption like in uWSGI- Here’s a deep read about how uWSGI solved it - https://uwsgi-docs.readthedocs.io/en/latest/articles/SerializingAccept.html
- Here’s how Clubhouse solved its thundering herd problem due to Gunicorn. A super fun read. Spoiler Alert - they end up using HAProxy for load balancing across multiple manually spawn master Gunicorn workers instead of letting Gunicorn load balance amongst itself.
- References:
- https://idea.popcount.org/2017-02-20-epoll-is-fundamentally-broken-12/
- https://man7.org/linux/man-pages/man2/select.2.html
- https://man7.org/linux/man-pages/man2/poll.2.html
- https://man7.org/linux/man-pages/man7/epoll.7.html
- https://man7.org/linux/man-pages/man2/epoll_ctl.2.html
- https://notes.shichao.io/unp/ch6/
- And of course, GPT
- TODOs:
- Read this article on Linux
accept()scalability - Read about
kqueuewhich is mentioned as a better successor to epoll. I could be wrong here but that’s what I read at places. - Checkout io_uring
- Read this article on Linux